Herbert A. Simon (1916–2001) was a multidisciplinary scholar who contributed significantly to artificial intelligence.
He is largely regarded as one of the twentieth century's
most prominent social scientists.
His contributions at Carnegie Mellon University lasted five
decades.
Early artificial intelligence research was driven by the
idea of the computer as a symbol manipulator rather than a number cruncher.
Emil Post, who originally wrote about this sort of
computational model in 1943, is credited with inventing production systems,
which included sets of rules for symbol strings used to establish
conditions—which must exist before rules can be applied—and the actions to be
done or conclusions to be drawn.
Simon and his Carnegie Mellon colleague Allen Newell
popularized these theories regarding symbol manipulation and production systems
by praising their potential benefits for general-purpose reading, storing, and
replicating, as well as comparing and contrasting various symbols and patterns.
Simon, Newell, and Cliff Shaw's Logic Theorist software was the first to employ symbol manipulation to construct "intelligent" behavior.
Theorems presented in Bertrand Russell and Alfred North
Whitehead's Principia Mathematica (1910) might be independently proved by logic
theorists.
Perhaps most notably, the Logic Theorist program uncovered a
shorter, more elegant demonstration of Theorem 2.85 in the Principia
Mathematica, which was subsequently rejected by the Journal of Symbolic Logic
since it was coauthored by a machine.
Although it was theoretically conceivable to prove the
Principia Mathematica's theorems in an exhaustively detailed and methodical
manner, it was impractical in reality due to the time required.
Newell and Simon were fascinated by the human rules of thumb
for solving difficult issues for which an extensive search for answers was
impossible due to the massive quantities of processing necessary.
They used the term "heuristics" to describe
procedures that may solve issues but do not guarantee success.
A heuristic is a "rule of thumb" used to solve a
problem that is too difficult or time consuming to address using an exhaustive
search, a formula, or a step-by-step method.
Heuristic approaches are often compared with algorithmic
methods in computer science, with the result of the method being a significant
differentiating element.
According to this contrast, a heuristic program will provide
excellent results in most cases, but not always, while an algorithmic program
is a clear technique that guarantees a solution.
This is not, however, a technical difference.
In fact, a heuristic procedure that consistently yields the
best result may no longer be deemed "heuristic"—alpha-beta pruning is
an example of this.
Simon's heuristics are still utilized by programmers who are
trying to solve issues that demand a lot of time and/or memory.
The game of chess is one such example, in which an
exhaustive search of all potential board configurations for the proper solution
is beyond the human mind's or any computer's capabilities.
Indeed, for artificial intelligence research, Herbert Simon and Allen Newell referred to computer chess as the Drosophila or fruit fly.
Heuristics may also be used to solve issues that don't have
a precise answer, such as in medical diagnosis, when heuristics are applied to
a collection of symptoms to determine the most probable diagnosis.
Production rules are derived from a class of cognitive
science models that apply heuristic principles to productions (situations).
In practice, these rules reduce down to "IF-THEN"
statements that reflect specific preconditions or antecedents, as well as the
conclusions or consequences that these preconditions or antecedents justify.
"IF there are two X's in a row, THEN put an O to
block," is a frequent example offered for the application of production
rules to the tic-tac-toe game.
These IF-THEN statements are incorporated into expert
systems' inference mechanisms so that a rule interpreter can apply production
rules to specific situations lodged in the context data structure or short-term
working memory buffer containing information supplied about that situation and
draw conclusions or make recommendations.
Production rules were crucial in the development of artificial intelligence as a discipline.
Joshua Lederberg, Edward Feigenbaum, and other Stanford
University partners would later use this fundamental finding to develop
DENDRAL, an expert system for detecting molecular structure, in the 1960s.
These production guidelines were developed in DENDRAL after
discussions between the system's developers and other mass spectrometry
specialists.
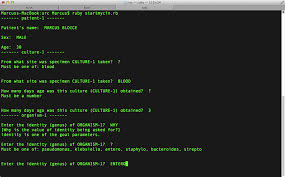
Edward Shortliffe, Bruce Buchanan, and Edward Feigenbaum
used production principles to create MYCIN in the 1970s.
MYCIN has over 600 IFTHEN statements in it, each reflecting
domain-specific knowledge about microbial illness diagnosis and treatment.
PUFF, EXPERT, PROSPECTOR, R1, and CLAVIER were among the
several production rule systems that followed.
Simon, Newell, and Shaw demonstrated how heuristics may overcome the drawbacks of classical algorithms, which promise answers but take extensive searches or heavy computing to find.
A process for solving issues in a restricted, clear sequence
of steps is known as an algorithm.
Sequential operations, conditional operations, and iterative
operations are the three kinds of fundamental instructions required to create
computable algorithms.
Sequential operations perform tasks in a step-by-step
manner.
The algorithm only moves on to the next job when each step
is completed.
Conditional operations are made up of instructions that ask
questions and then choose the next step dependent on the response.
One kind of conditional operation is the "IF-THEN"
expression.
Iterative operations run "loops" of instructions.
These statements tell the task flow to go back and repeat a
previous series of statements in order to solve an issue.
Algorithms are often compared to cookbook recipes, in which
a certain order and execution of actions in the manufacture of a product—in
this example, food—are dictated by a specific sequence of set instructions.
Newell, Shaw, and Simon created list processing for the Logic Theorist software in 1956.
List processing is a programming technique for allocating
dynamic storage.
It's mostly utilized in symbol manipulation computer
applications like compiler development, visual or linguistic data processing,
and artificial intelligence, among others.
Allen Newell, J. Clifford Shaw, and Herbert A. Simon are credited with creating the first list processing software with enormous, sophisticated, and flexible memory structures that were not reliant on subsequent computer/machine memory.
List processing techniques are used in a number of
higher-order languages.
IPL and LISP, two artificial intelligence languages, are the
most well-known.
Simon and Newell's Generic Problem Solver (GPS) was
published in the early 1960s, and it thoroughly explains the essential
properties of symbol manipulation as a general process that underpins all types
of intelligent problem-solving behavior.
GPS formed the foundation for decades of early AI research.
To arrive at a solution, General Problem Solver is a
software for a problem-solving method that employs means-ends analysis and
planning.
GPS was created with the goal of separating the
problem-solving process from information particular to the situation at hand,
allowing it to be used to a wide range of issues.
Simon is an economist, a political scientist, and a
cognitive psychologist.
Simon is known for the notions of limited rationality,
satisficing, and power law distributions in complex systems, in addition to his
important contributions to organizational theory, decision-making, and
problem-solving.
Computer and data scientists are interested in all three
themes.
Human reasoning is inherently constrained, according to
bounded rationality.
Humans lack the time or knowledge required to make ideal
judgments; problems are difficult, and the mind has cognitive limitations.
Satisficing is a term used to describe a decision-making
process that produces a solution that "satisfies" and
"suffices," rather than the most ideal answer.
Customers use satisficing in market conditions when they
choose things that are "good enough," meaning sufficient or
acceptable.
Simon described how power law distributions were obtained from preferred attachment mechanisms in his study on complex organizations.
When a relative change in one variable induces a
proportionate change in another, power laws, also known as scaling laws, come
into play.
A square is a simple illustration; when the length of a side
doubles, the square's area quadruples.
Power laws may be found in biological systems, fractal
patterns, and wealth distributions, among other things.
Preferential attachment processes explain why the affluent
grow wealthier in income/wealth distributions: Individuals' wealth is dispersed
according on their current level of wealth; those with more wealth get
proportionately more income, and hence greater overall wealth, than those with
less.
When graphed, such distributions often create so-called long
tails.
These long-tailed distributions are being employed to
explain crowdsourcing, microfinance, and online marketing, among other things.
Simon was born in Milwaukee, Wisconsin, to a Jewish electrical engineer with multiple patents who came from Germany in the early twentieth century.
His mother was a musical prodigy. Simon grew interested in the social sciences after reading books on psychology and economics written by an uncle.
He has said that two works inspired his early thinking on
the subjects: Norman Angell's The Great Illusion (1909) and Henry George's
Progress and Poverty (1879).
Simon obtained his doctorate in organizational decision-making from the University of Chicago in 1943.
Rudolf Carnap, Harold Lasswell, Edward Merriam, Nicolas
Rashevsky, and Henry Schultz were among his instructors.
He started his career as a political science professor at
the Illinois Institute of Technology, where he taught and conducted research.
In 1949, he transferred to Carnegie Mellon University, where
he stayed until 2001.
He progressed through the ranks of the Department of
Industrial Management to become its chair.
He has written twenty-seven books and several articles that
have been published.
In 1959, he was elected a member of the American Academy of
Arts and Sciences.
In 1975, Simon was awarded the coveted Turing Award, and in
1978, he was awarded the Nobel Prize in Economics.
Find Jai on Twitter | LinkedIn | Instagram
You may also want to read more about Artificial Intelligence here.
See also:
Dartmouth AI Conference; Expert Systems; General Problem Solver; Newell, Allen.
References & Further Reading:
Crowther-Heyck, Hunter. 2005. Herbert A. Simon: The Bounds of Reason in Modern America. Baltimore: Johns Hopkins Press.
Newell, Allen, and Herbert A. Simon. 1956. The Logic Theory Machine: A Complex Information Processing System. Santa Monica, CA: The RAND Corporation.
Newell, Allen, and Herbert A. Simon. 1976. “Computer Science as Empirical Inquiry: Symbols and Search.” Communications of the ACM 19, no. 3: 113–26.
Simon, Herbert A. 1996. Models of My Life. Cambridge, MA: MIT Press.