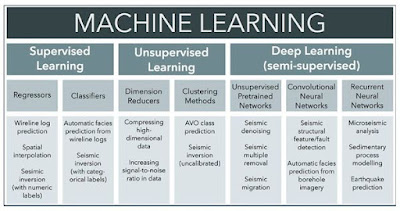
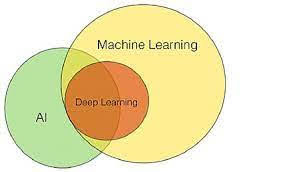
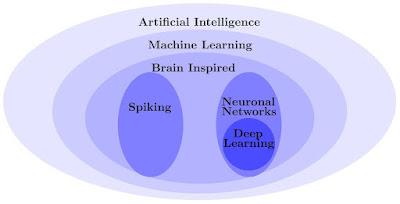
Deep
learning is a subset of methods, tools, and techniques in artificial intelligence or machine learning.
Learning in this case involves the ability to derive
meaningful information from various layers or representations of any given data
set in order to complete tasks without human instruction.
Deep refers to the depth of a learning algorithm, which
usually involves many layers.
Machine learning networks involving many layers are often
considered to be deep, while those with only a few layers are considered
shallow.
The recent rise of deep learning over the 2010s is largely
due to computer hardware advances that permit the use of computationally
expensive algorithms and allow storage of immense datasets.
Deep learning has produced exciting results in the fields of
computer vision, natural language, and speech recognition.
Notable examples of its application can be found in personal
assistants such as Apple’s Siri or Amazon Alexa and search, video, and product
recommendations.
Deep learning has been used to beat human champions at
popular games such as Go and Chess.
Artificial neural networks are the most common form of deep
learning.
Neural networks extract information through multiple stacked
layers commonly known as hidden layers.
These layers contain artificial neurons, which are connected
independently via weights to neurons in other layers.
Neural networks often involve dense or fully connected
layers, meaning that each neuron in any given layer will connect to every
neuron of its preceding layer.
This allows the network to learn increasingly intricate
details or be trained by the data passing through each subsequent layer.
Part of what separates deep learning from other forms of
machine learning is its ability to work with unstructured data.
There are no pre-arranged labels or characteristics in
unstructured data.
Deep learning algorithms can learn to link their own
features with unstructured inputs using several stacked layers.
This is done by the hierarchical approach in which a deep
multi-layered learning algorithm offers more detailed information with each
successive layer, enabling it to break down a very complicated issue into a
succession of lesser ones.
This enables the network to learn more complex information
or to be taught by data provided via successive layers.
The following steps are used to train a network: Small batches
of tagged data are sent over the network first.
The loss of the network is determined by comparing
predictions to real labels.
Back propagation is used to compute and transmit any
inconsistencies to the weights.
Weights are tweaked gradually in order to keep losses to a
minimum throughout each round of predictions.
The method is repeated until the network achieves optimum
loss reduction and high accuracy of accurate predictions.
Deep learning has an advantage over many machine learning
approaches and shallow learning networks since it can self-optimize its layers.
Machine or shallow learning methods need human participation
in the preparation of unstructured data for input, often known as feature
engineering, since they only have a few layers at most.
This may be a lengthy procedure that takes much too much
time to be profitable, particularly if the dataset is enormous.
As a result of these factors, machine learning algorithms
may seem to be a thing of the past.
Deep learning algorithms, on the other hand, come at a
price.
Finding their own characteristics requires a large quantity
of data, which isn't always accessible.
Furthermore, as data volumes get larger, so do the
processing power and training time requirements, since the network will be
dealing with a lot more data.
Depending on the number and kinds of layers utilized,
training time will also rise.
Fortunately, online computing, which lets anybody to rent
powerful machines for a price, allows anyone to run some of the most demanding
deep learning networks.
Convolutional neural networks need hidden layers that are
not included in the standard neural network design.
Deep learning of this kind is most often connected with
computer vision projects, and it is now the most extensively used approach in
that sector.
In order to obtain information from an image, basic convnet
networks would typically utilize three kinds of layers: convolutional layers,
pooling layers, and dense layers.
Convolutional layers gather information from low-level
features such as edges and curves by sliding a window, or convolutional kernel,
over the picture.
Subsequent stacked convolutional layers will repeat this
procedure over the freshly generated layers of low-level features, looking for
increasingly higher-level characteristics until the picture is fully
understood.
Different hyperparameters may be modified to find different
sorts of features, such as the size of the kernel or the distance it glides
over the picture.
Pooling layers enable a network to learn higher-level
elements of an image in a progressive manner by down sampling the picture along
the way.
The network may become too computationally costly without a
pooling layer built amid convolutional layers as each successive layer examines
more detailed data.
In addition, the pooling layer reduces the size of an image
while preserving important details.
These characteristics become translation invariant, which
means that a feature seen in one portion of an image may be identified in a
totally other region of the same picture.
The ability of a convolutional neural network to retain
positional information is critical for image classification.
The ability of deep learning to automatically parse through
unstructured data to find local features that it deems important while
retaining positional information about how these features interact with one
another demonstrates the power of convolutional neural networks.
Recurrent neural networks excel at sequence-based tasks like
sentence completion and stock price prediction.
The essential idea is that, unlike previous instances of
networks in which neurons just transmit information forward, neurons in
recurrent neural networks feed information forward while also periodically
looping the output back to itself throughout a time step.
Recurrent neural networks may be regarded of as having a
rudimentary type of memory since each time step includes recurrent information
from all previous time steps.
This is often utilized in natural language processing
projects because recurrent neural networks can handle text in a way that is
more human-like.
Instead of seeing a phrase as a collection of isolated
words, a recurrent neural network may begin to analyse the mood of the
statement or even create the following sentence autonomously depending on what
has already been stated.
In many respects akin to human talents, deep learning may
give strong techniques of evaluating unstructured data.
Unlike humans, deep learning networks never get tired.
Deep learning may substantially outperform standard machine
learning techniques when given enough training data and powerful computers,
particularly given its autonomous feature engineering capabilities.
Image classification, voice recognition, and self-driving
vehicles are just a few of the fields that have benefited tremendously from
deep learning research over the previous decade.
Many new exciting deep learning applications will emerge if
current enthusiasm and computer hardware upgrades continue to grow.
~ Jai Krishna Ponnappan
You may also want to read more about Artificial Intelligence here.
See also:
Automatic Film Editing; Berger-Wolf, Tanya; Cheng, Lili; Clinical Decision Support Systems; Hassabis, Demis; Tambe, Milind.
Further Reading:
Chollet, François. 2018. Deep Learning with Python. Shelter Island, NY: Manning Publications.
Géron, Aurélien. 2019. Hands-On Machine Learning with Scikit-Learn, Keras and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. Second edition. Sebastopol, CA: O’Reilly Media.
Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2017. Deep Learning. Cambridge, MA: MIT Press.