Lethal Autonomous Weapons Systems.(LAWS), also known as
"lethal autonomous weapons," "robotic weapons," or
"killer robots," are unmanned robotic systems that can choose and
engage targets autonomously and determine whether or not to employ lethal
force.
While human-like robots waging wars or utilizing fatal force against people are common in popular culture (ED-209 in RoboCop, T-800 in The Terminator, etc. ), fully autonomous robots are still under development.
LAWS raise serious ethical issues, which are increasingly
being contested by AI specialists, NGOs, and the international community.
While the concept of autonomy varies depending on the debate
over LAWS, it is often defined as "the capacity to select and engage a
target without further human interference after being commanded to do so"
(Arkin 2017).
However, according on their amount of autonomy, LAWS are typically categorized into three categories:
1. Weapons with a person in the loop: These weapons can only identify targets and deliver force in response to a human order.
2. Weapons with a person on the loop: These weapons may choose targets and administer force while being monitored by a human supervisor who can overrule their actions.
3. Human-out-of-the-loop weapons: they can choose targets and deliver force without any human involvement or input.
These three categories of unmanned weapons are covered under
the LAWS.
The phrase "totally autonomous weapons" applies to
both human-out-of-the-loop and "human-on-the-loop weapons" (or
weapons with monitored autonomy) if the monitoring is restricted (for example,
if their response time cannot be matched by a human operator).
Robotic weapons aren't a new concept.
Anti-tank mines, for example, have been frequently utilized
since World War II (1939–1945), when they were first activated by a human and
then engaged targets on their own.
Furthermore, LAWS covers a wide range of unmanned weapons
with varying degrees of autonomy and lethality, ranging from ground mines to
remote-controlled Unmanned Combat Aerial Vehicles (UCAV), also known as com bat
drones, and fire-and-forget missiles.
To far, the only weapons in use that have total autonomy are
"defensive" systems (such as landmines).
Neither completely "offensive" autonomous lethal
weapons nor machine learning-based LAWS have been deployed yet.
Even though military research is often kept secret, it is
known that a number of nations (including the United States, China, Russia, the
United Kingdom, Israel, and South Korea) are significantly investing in
military AI applications.
The inter-national AI arms race, which began in the early
2010s, has resulted in a rapid pace of progress in this sector, with fully
autonomous deadly weapons on the horizon.
There are numerous obvious forerunners of such weapons.
The MK 15 Phalanx CIWS, for example, is a close-in weapon
system capable of autonomously performing search, detection, evaluation,
tracking, engagement, and kill assessment duties.
It is primarily used by the US Navy.
Another example is Israel's Harpy, a self-destructing
anti-radar "fire-and-forget" drone that is dispatched without a
specified target and flies a search pattern before attacking targets.
The deployment of LAWS has the potential to revolutionize
combat in the same way as gunpowder and nuclear weapons did earlier.
It would eliminate the distinction between fighters and
weaponry, and it would make battlefield delimitation more difficult.
However, LAWS may be linked to a variety of military
advantages.
Their employment would undoubtedly be a force multiplier,
reducing the number of human warriors on the battlefield.
As a result, military lives would be saved.
Because to its quicker reaction time, capacity to undertake
movements that human fighters cannot (due to human physical restrictions), and
ability to make more efficient judgments (from a military viewpoint), LAWS may
be superior to many conventional weapons in terms of force projection.
The use of LAWS, on the other hand, involves significant
ethical and political difficulties.
In addition to violating the "Three Laws of
Robotics," the deployment of LAWS might lead to the normalization of
deadly force, since armed confrontations involve less and fewer human fighters.
Some argue that LAWS are a danger to mankind in this way.
Concerns about the use of LAWS by non-state organizations
and nations in non-international armed situations have also been raised.
Delegating life-or-death choices to computers might be seen
as a violation of human dignity.
Furthermore, the capacity of LAWS to comply with the norms
of international humanitarian law, particularly the rules of proportionality
and military necessity, is frequently contested.
Despite their lack of compassion, others claim that LAWS
would not act on emotions like as rage, which may lead to purposeful pain such
as torture or rape.
Given the difficult difficulty of avoiding war crimes, as
seen by countless incidents in previous armed conflicts, it is even possible to
claim that LAWS might commit fewer crimes than human warriors.
The effect of LAWS deployment on noncombatants is also a hot
topic of debate.
Some argue that the adoption of LAWS will result in fewer
civilian losses (Arkin 2017), since AI may be more efficient in decision-making
than human warriors.
Some detractors, however, argue that there is a greater
chance of bystanders getting caught in the crossfire.
Furthermore, the capacity of LAWS to adhere to the principle
of distinction is a hot topic, since differentiating fighters from civilians
may be particularly difficult, especially in non-international armed conflicts
and asymmetric warfare.
Because they are not moral actors, LAWS cannot be held
liable for any of their conduct.
This lack of responsibility may cause further suffering to
war victims.
It may also inspire war crimes to be committed.
However, it is debatable whether the authority that chose to
deploy LAWS or the persons who created or constructed it have moral
culpability.
LAWS has attracted a lot of scientific and political
interest in the recent 10 years.
Eighty-seven non-governmental organizations have joined the
group that began the "Stop Killer Robots" campaign in 2012.
Civil society mobilizations have emerged from its campaign
for a preemptive prohibition on the creation, manufacturing, and use of LAWS.
A statement signed by over 4,000 AI and robotics academics
in 2016 called for a ban on LAWS.
Over 240 technology businesses and organizations promised
not to engage in or promote the creation, manufacturing, exchange, or use of
LAWS in 2018.
Because current international law may not effectively handle
the challenges created by LAWS, the UN's Convention on Certain Conventional
Weapons launched a consultation process on the subject.
It formed a Group of Governmental Experts in 2016. (GGE).
Due to a lack of consensus and the resistance of certain nations, the GGE has yet to establish an international agreement to outlaw LAWS (especially the United States, Russia, South Korea, and Israel).
However, twenty-six UN member nations have backed the
request for a ban on LAWS, and the European Parliament passed a resolution in
June 2018 asking for "an international prohibition on weapon systems that
lack human supervision over the use of force." Because there is no example
of a technical invention that has not been employed, LAWS will almost certainly
be used in the future of conflict.
Nonetheless, there is widespread agreement that humans
should be kept "in the loop" and that the use of Regulations should
be governed by international and national laws.
However, as the deployment of nuclear and chemical weapons,
as well as anti-personal landmines, has shown, a worldwide legal prohibition on
the use of LAWS is unlikely to be enforced by all governments and non-state
groups.
Hacking the Mac Mac Hack IV, a 1967 chess software built by
Richard Greenblatt, gained notoriety for being the first computer chess program
to engage in a chess tournament and to play adequately against humans,
obtaining a USCF rating of 1,400 to 1,500.
Greenblatt's software, written in the macro assembly
language MIDAS, operated on a DEC PDP-6 computer with a clock speed of 200
kilohertz.
While a graduate student at MIT's Artificial Intelligence
Laboratory, he built the software as part of Project MAC.
"Chess is the drosophila [fruit fly] of artificial
intelligence," according to Russian mathematician Alexander Kronrod, the
field's chosen experimental organ ism (Quoted in McCarthy 1990, 227).
Creating a champion chess software has been a cherished goal
in artificial intelligence since 1950, when Claude Shan ley first described
chess play as a task for computer programmers.
Chess and games in general involve difficult but
well-defined issues with well-defined rules and objectives.
Chess has long been seen as a prime illustration of
human-like intelligence.
Chess is a well-defined example of human decision-making in
which movements must be chosen with a specific purpose in mind, with limited
knowledge and uncertainty about the result.
The processing capability of computers in the mid-1960s
severely restricted the depth to which a chess move and its alternative answers
could be studied since the number of different configurations rises
exponentially with each consecutive reply.
The greatest human players have been proven to examine a
small number of moves in greater detail rather than a large number of moves in
lower depth.
Greenblatt aimed to recreate the methods used by good
players to locate significant game tree branches.
He created Mac Hack to reduce the number of nodes analyzed
while choosing moves by using a minimax search of the game tree along with
alpha-beta pruning and heuristic components.
In this regard, Mac Hack's style of play was more human-like
than that of more current chess computers (such as Deep Thought and Deep Blue),
which use the sheer force of high processing rates to study tens of millions of
branches of the game tree before making moves.
In a contest hosted by MIT mathematician Seymour Papert in
1967, Mac Hack defeated MIT philosopher Hubert Dreyfus and gained substantial
renown among artificial intelligence researchers.
The RAND Corporation published a mimeographed version of
Dreyfus's paper, Alchemy and Artificial Intelligence, in 1965, which criticized
artificial intelligence researchers' claims and aspirations.
Dreyfus claimed that no computer could ever acquire
intelligence since human reason and intelligence are not totally rule-bound,
and hence a computer's data processing could not imitate or represent human
cognition.
In a part of the paper titled "Signs of
Stagnation," Dreyfus highlighted attempts to construct chess-playing
computers, among his many critiques of AI.
Mac Hack's victory against Dreyfus was first seen as
vindication by the AI community.
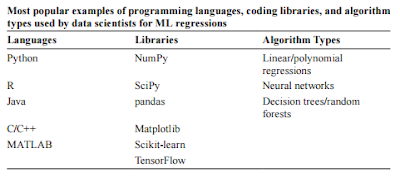
Machine Learning Regressions are a kind of regression that
is used in machine learning.
"Machine learning," a phrase originated by Arthur
Samuel in 1959, is a kind of artificial intelligence that produces results
without requiring explicit programming.
Instead, the system learns from a database on its own and
improves over time.
Machine learning techniques have a wide range of
applications (e.g., computer vision, natural language processing, autonomous
gaming agents, classification, and regressions) and are used in practically
every sector due to their resilience and simplicity of implementation (e.g.,
tech, finance, research, education, gaming, and navigation).
Machine learning algorithms may be generically classified
into three learning types: supervised, unsupervised, and reinforcement,
notwithstanding their vast range of applications.
Supervised learning is exemplified by machine learning
regressions.
They use algorithms that have been trained on data with
labeled continuous numerical outputs.
The quantity of training data or validation criteria
required once the regression algorithm has been suitably trained and verified
will depend on the issues being addressed.
For data with comparable input structures, the newly
developed predictive models give inferred outputs.
These aren't static models.
They may be updated on a regular basis with new training
data or by displaying the actual right outputs on previously unlabeled inputs.
Despite machine learning methods' generalizability, there is
no one program that is optimal for all regression issues.
When choosing the best machine learning regression method
for the present situation, there are a lot of things to think about (e.g.,
programming languages, available libraries, algo rithm types, data size, and
data structure).
There are machine learning programs that employ single or
multivariable linear regression approaches, much like other classic statistical
methods.
These models represent the connections between a single or
several independent feature variables and a dependent target variable.
The models provide linear representations of the combined
input variables as their output.
These models are only applicable to noncomplex and small
data sets.
Polynomial regressions may be used with nonlinear data.
This necessitates the programmers' knowledge of the data
structure, which is often the goal of utilizing machine learning models in the
first place.
These methods are unlikely to be appropriate for most
real-world data, but they give a basic starting point and might provide users
with models that are straightforward to understand.
Decision trees, as the name implies, are tree-like
structures that map the input features/attributes of programs to determine the
eventual output goal.
The answer to the condition of that node splits into edges
in a decision tree algorithm, which starts with the root node (i.e., an input
variable).
A leaf is defined as an edge that no longer divides; an
internal edge is defined as one that continues to split.
For example, age, weight, and family diabetic history might
be used as input factors in a dataset of diabetic and nondiabetic patients to
estimate the likelihood of a new patient developing diabetes.
The age variable might be used as the root node (e.g., age
40), with the dataset being divided into those who are more than or equal to 40
and those who are 39 and younger.
The model provides that leaf as the final output if the
following internal node after picking more than or equal to 40 is whether or
not a parent has/had diabetes, and the leaf estimates the affirmative responses
to have a 60% likelihood of this patient acquiring diabetes.
This is a very basic decision tree that demonstrates the
decision-making process.
Thousands of nodes may readily be found in a decision tree.
Random forest algorithms are just decision tree mashups.
They are made up of hundreds of decision trees, the ultimate
outputs of which are the averaged outputs of the individual trees.
Although decision trees and random forests are excellent at
learning very complex data structures, they are prone to overfitting.
With adequate pruning (e.g., establishing the n values
limits for splitting and leaves) and big enough random forests, overfitting may
be reduced.
Machine learning techniques inspired by the neural
connections of the human brain are known as neural networks.
Neurons are the basic unit of neural network algorithms,
much as they are in the human brain, and they are organized into numerous
layers.
The input layer contains the input variables, the hidden
layers include the layers of neurons (there may be numerous hidden levels), and
the output layer contains the final neuron.
A single neuron in a feedforward process
(a) takes the input feature variables,
(b) multiplies the feature values by a weight,
(c) adds the resultant feature products, together with a bias variable, and
(d) passes the sums through an activation function, most often a sigmoid function.
The partial derivative computations of the previous neurons
and neural layers are used to alter the weights and biases of each neuron.
Backpropagation is the term for this practice.
The output of the activation function of a single neuron is
distributed to all neurons in the next hidden layer or final output layer.
As a result, the projected value is the last neuron's
output.
Because neural networks are exceptionally adept at learning
exceedingly complicated variable associations, programmers may spend less time
reconstructing their data.
Neural network models, on the other hand, are difficult to
interpret due to their complexity, and the intervariable relationships are
largely hidden.
When used on extremely big datasets, neural networks operate
best.
They need meticulous hyper-tuning and considerable
processing capacity.
For data scientists attempting to comprehend massive
datasets, machine learning has become the standard technique.
Machine learning systems are always being improved in terms
of accuracy and usability by researchers.
Machine learning algorithms, on the other hand, are only as
useful as the data used to train the model.
Poor data produces dramatically erroneous outcomes, while biased data combined with a lack of knowledge deepens societal disparities.
You may also want to read more about Artificial Intelligence here.
See also:
Autonomous Weapons Systems, Ethics of; Battlefield AI and Robotics.
Further Reading:
Arkin, Ronald. 2017. “Lethal Autonomous Systems and the Plight of the Non-Combatant.” In The Political Economy of Robots, edited by Ryan Kiggins, 317–26. Basingstoke, UK: Palgrave Macmillan.
Heyns, Christof. 2013. Report of the Special Rapporteur on Extrajudicial, Summary, or Arbitrary Executions. Geneva, Switzerland: United Nations Human Rights Council. http://www.ohchr.org/Documents/HRBodies/HRCouncil/RegularSession/Session23/A-HRC-23-47_en.pdf.
Human Rights Watch. 2012. Losing Humanity: The Case against Killer Robots. https://www.hrw.org/report/2012/11/19/losing-humanity/case-against-killer-robots.
Krishnan, Armin. 2009. Killer Robots: Legality and Ethicality of Autonomous Weapons. Aldershot, UK: Ashgate.
Roff, Heather. M. 2014. “The Strategic Robot Problem: Lethal Autonomous Weapons in War.” Journal of Military Ethics 13, no. 3: 211–27.
Simpson, Thomas W., and Vincent C. Müller. 2016. “Just War and Robots’ Killings.” Philosophical Quarterly 66, no. 263 (April): 302–22.
Singer, Peter. 2009. Wired for War: The Robotics Revolution and Conflict in the 21st Century. New York: Penguin.
Sparrow, Robert. 2007. “Killer Robots.” Journal of Applied Philosophy 24, no. 1: 62–77.